



Last month, I had the privilege of attending the 2019 Neural Information Processing Systems (NeurIPS) conference in Vancouver, Canada. It is widely recognized as the biggest and most influential conference by the Machine Learning (ML) community, and most of those who are interested in the future of the Artificial Intelligence (AI) field keep their eye on it. Yearly, breakthrough theoretical ideas are announced, received with great anticipation and enthusiasm by the community for debate, and some successfully transform the landscape of our understanding of how these systems work, and how they could work even better. Many great minds are undoubtedly in attendance to present their ideas, and the biggest heavyweight industrial players in the space - Google, Facebook, etc. - prowl the attendee lists for top talent to poach and hire. It is quite a spectacle to behold, which when experienced in person has the potential to re-invigorate and re-excite an AI researcher about the future of their area of endeavor.
This year, a total of 13000 registrants were reportedly in physical attendance. For comparison of scale, the blockbuster SXSW music, film and tech festival in Austin, Texas, USA - which spans a couple weeks - reportedly attracts approximately 72000 *registered* attendees each year – a number not that much larger than NeurIPS, which is an academic conference focused on a very specific technical area. The enthusiasm for AI is quite remarkable (see Fig 1 below). In fact, the rush for NeurIPS tickets I witnessed last year is the greatest such rush I have personally witnessed - this includes my numerous experiences with SXSW, ACL, and similar blockbuster music festivals. Thankfully the organizers initiated a ticket lottery this year, keeping things more sane.

This is the second year in a row I am attending, also having visited NeurIPS 2018 in Montreal. My dissertation work was in the area of mathematical optimization – an area intricately linked with AI/ML, but still being somewhat of a different community and focus – and as such I did not intersect with NeurIPS much prior, being only vaguely aware of it. After my industrial experience leading teams to tackle some interesting research problems in Automatic Machine Learning (AutoML) and Natural Language Processing (NLP) for a pair of open source DARPA projects, I got invited to serve on some Program Committees – reviewing papers and supporting some mentorship efforts at NeurIPS 2018 and 2019. I have been very grateful for this opportunity to get involved in the AI community since, and would like to encourage anyone reading this and considering volunteering their time similarly to go ahead and do it. It is one of the most effective ways to stay abreast of a rapidly evolving field, if nothing else.
Personally, through this experience I was particularly struck by how much more accessible and powerful these technologies are becoming every year, yet how little of it is being adopted to solve problems faced by communities most in need. This conundrum is mostly based in the asymmetry of participation – you don’t run into too many researchers from Ghana at NeurIPS, for instance. Among many other things, it has encouraged me to start this blog, where I can share tips, tricks, resources and information I discover through such experiences in the hope of potentially helping in a miniscule way the next researcher – with some adjacency to me – with the ambition to leverage this very exciting field.
In this my very first blog post, I will cover which topics stood out to me personally when I attended NeurIPS 2019. My goal is to highlight topics that struck me as potentially being generally transformative to AI over the next few years, while also being attentive to topics that excite me personally, or are particularly relevant to many people I care about. In no way should this description be considered to be complete – it is possible, indeed likely, that some very powerful ideas are not listed here, due to limits on the sheer volume of subject matter an individual can digest in a finite time. The topics I do cover, I have grouped into rough categories by section.

All papers and recorded talk videos are available freely online. While it is true that the aforementioned “asymmetry of participation in AI” is partly due to insidious and uncontrollable factors such as visa denials for researchers from certain regions, it is increasingly the case that barriers to information access are falling. All talks are streamed live online at https://neurips.cc/ and are archived for later viewing.
Neural Networks
The first idea that stuck out to me was the Legendre Memory Unit (LMU) (talk video), which in short can be thought about as a sort of replacement for the Long Short Term Memory (LSTM) recurrent neural network (rNN) architecture. LSTMs have numerous applications, from speech recognition to time series analysis, music composition and beyond. They crop up naturally when sequences are being studied. They were introduced to improve the ability of rNN architectures to handle longer term dependencies in such sequences. LMUs claim to handle long-term dependencies even better, by solving a system of coupled ordinary differential equations (ODEs) to express the LMU's time evolution in a clever way. The use of Legendre polynomials allows the authors to orthogonalize the ODE solution trajectories in a scale-invariant way, which is the source of the method’s useful properties. The sheer number of potential applications that could be touched by this method suggests that this could be a truly transformative method.
Deep Equilibrium Neural Networks is another idea, pertaining to neural networks, that drew my attention. It claims to outline a constant-memory neural network architecture by using a root-finding procedure to “represent an infinite number of layers”. This is motivated by the observation that "a neural network’s hidden layers often converge to a fixed point". If this is fully workable in practice, this could enable researchers solve significantly deeper neural network models than is presently possible, and the impact of such an advance cannot be overstated.
Adversarial Machine Learning
Adversarial machine learning is an idea that has a lot of buzz within ML. It is centered around the idea of attempting to deceive a trained model with input to make it fail. By making two such models – an adversary and the trained model or discriminator – play each other at length, the adversary can learn to generate convincing photographs, good training data, etc. In particular, it has been discovered that adding seemingly random noise to input can completely confuse many models., e.g., in the figure below a model has been deceived to think that a pig is actually an airplane. This naturally raises concerns for cyber security and robustness, and for a long time these have been thought of as “bugs” in the models, akin to optical illusions in humans which are often perceived to as “evolution’s mistakes”.
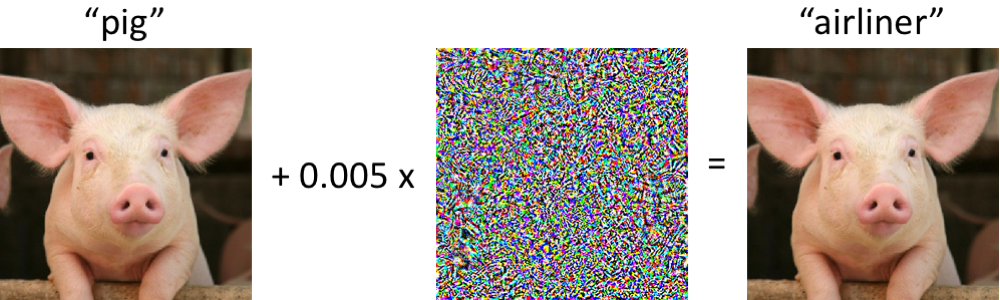
The paper entitled “Adversarial Examples are Not Bugs, They are Features” challenges that assertion in the manner indicated by the self-explanatory title. The authors conduct a set of experiments to demonstrate that perhaps this phenomenon is not due to "bugs", but rather features imperceptible to humans that are nevertheless meaningful and very important to how these systems work. This is a very new and potentially influential idea, and unsurprisingly I sensed a bit of push back around the idea, indicating the issue is far from settled.
Transfer Learning
Unsurprisingly, Transfer Learning was a big theme at the conference, permeating every subfield present at the conference. Notably, Yoshua Bengio’s Posner Lecture discussed what it would take to move from good “System 1” performance we see from AI systems today to good “System 2” performance more akin to human intelligence that we hope these systems will eventually achieve. He emphasized modularity, and proposed a sparse factor graph model, as a potential solution to inference under changing data and task distributions. He argues that this constrains the system to learn the types of causal relationships that are key to learning in the real world, and believes the impact of such an approach will be analogous and on par to the impact attention mechanisms have had recently in Natural Language Processing (NLP) – more on this in a couple sections later below. Beyond that there were works discussing better normalization methods for transfer learning of neural networks, new transfer learning techniques for reinforcement learning, as well as novel interpretable multisource transfer learning techniques which improve learning from multiple pretrained models.
Interpretability
Speaking of interpretability, naturally this was a big focus for a few different tracks at the conference. The ML community has been under increasing pressure to make our algorithms more interpretable and “fair” – in the sense that it should not discriminate against any specific subset of the population. A prominent example of this is banking, where it has become important that decisions not to grant loans to specific individuals are clearly explained to them, so that they can correct course for the future as needed, as well as to ensure lack of subjective bias of any sort. Notably, Bin Yu’s Breiman Lecture promoted this idea by discussing the principles behind Veridical Data Science – which seeks to ensure that related “information is reliable, reproducible, and clearly communicated so that empirical evidence may be evaluated in the context of human decisions”.
Natural Language Processing (NLP)
The theme of interpretability was particularly prominent for the Natural Language Processing (NLP) works at the conference. AllenNLP – the creators of the ELMo architecture, which sparked the recent pretrained Language model craze that includes its successor BERT – presented their NLP interpretability system “Interpret” as a demo. Interpretability is particularly important for NLP, given that recently all of the state-of-the-art models are neural network models which often come across as “black boxes” with no particular explanation for how they arrive at their predictions. This has been changing somewhat lately, with the attention-based models such as BERT having the ability to visualize which inputs are most important for an output being considered. An example of such a visualization, called a saliency map , is shown in the figure below. This tool is freely available online.

Another related visualization technique for NLP at the conference was exBERT - an interactive visualization tool that can be used to explore the predictions of a BERT embedding and build more detailed intuition for its behavior.
An intriguing work from the intersection between algorithms and the human brain, named “Inducing Brain-relevant bias in natural language processing models”, caught my attention. It showed that a BERT model can be fine-tuned to predict recordings of brain activity, e.g., functional MRI etc., across multiple human subjects, suggesting a link between modern NLP models and brain activity.
Topic modeling is a very important subject for modern social-media-driven societies. As such, I am always on the hunt for new advances in the area. When I decided to check out the crowd in front of one particular poster, it appears to have been for this very reason (look back to Fig 2). This was related to the work “Discriminative Topic Modeling with Logistic LDA”, which developed a discriminative variant of the traditional Latent Dirichlet Allocation or LDA model that is used widely for topic modeling of social media today. The traditional LDA model is a generative one, in the sense that it models the distribution of observed data, and this latest variant is discriminative in that it focuses on the decision boundary between classes of data points. This offers it some advantages, such as better interpretability (!!) and the ability to construct more complex representations for class boundaries and thereby superior performance on problems such as classification [more on the difference between these types of models here].
A rapidly evolving field like NLP is razor-focused on developing better benchmarks to compare newly emerging methods in previously unexplored ways. A benchmark which has emerged in NLP and has been very influential recently is the General Language Understanding Evaluation (GLUE) score (compare with Bilingual Evaluation Understudy or BLUE score for the quality of translations specifically). Bring in SuperGLUE – an enhanced successor to GLUE from its original authors – presented at NeurIPS 2019. This new benchmark was designed to be more challenging to the algorithms being compared, to provide “headroom” for further research. Both benchmarks GLUE and SuperGLUE are developed to encourage transfer learning across a variety of diverse NLP tasks.
NLP for African Languages
Recently, attention has been turning to the fact that most AI/ML resources are being focused on a few popular languages, such as English, French, Chinese, Russian, German, etc., at the expense of “lower resource” languages, such as many African Languages. Here, “low resource” just means lower availability of high quality data, which sometimes correlates with lower use of the internet by the ethnic speakers in question. Sometimes, the linguistic differences between high and low resource languages prohibit the direct application of well-known NLP methods to them, and this has been driving some fascinating research.
While browsing the posters sponsored by the Black in AI group at the conference, I was stricken by how many works on Ethiopian languages were present, and how little work was present for any Ghanaian languages (accepted works to the group can be found here ). Indeed, the paper which evaluated the quality of the existing BERT and FastText Yoruba/Twi embeddings, and found them to be absolutely awful is the first such work I have seen.
Armed with this observation, I dug further and confirmed to myself that while the interest in this subject has been surging, manifesting itself most relevantly as the upcoming AfricaNLP workshop in Addis Ababa (at ICLR 2020 – the first time this conference is to be held in Africa!), certain regions of Africa are being left behind. Reviewing the AfricaNLP link above, one will find research efforts focused on major Southern and Eastern African languages, with a smaller footprint on some Nigerian languages. Concerned with the absence of work targeting Ghanaian languages in particular, and West African languages in general, I spoke with some of my colleagues – among them Demba Ba and Stephen E. Moore – and we unanimously agreed to begin looking for a way to close this gap.
Ghana NLP
All this culminated with the formation of Ghana NLP – an Open Source Initiative focused on Natural Language Processing (NLP) of Ghanaian Languages, and its Applications to Local Problems. I am incredibly excited about what lies ahead. Our goal is to initially approach the Africa NLP problem from the Ghanaian language angle, an important economy and culture in Africa which so far has been ignored in this regard (we don’t even have a Google Translate equivalent for major languages such as Twi! How? It is 2020 already!). We hope to scale any lessons learned to aid efforts in the rest of the continent. Please join us via our website above if you have an interest in the subject – it is an open source initiative, and all are welcome to join regardless of skill level. We hope to simultaneously provide an opportunity for emerging ML/AI talent to further hone their skills, and mentor them in the process, through this program.
Conclusion
The health of the field of Machine Learning and Artificial Intelligence is as vibrant as ever. Opportunities to create new value in old industries are nearly endless, and if one can visit one conference a year to try catch a glimpse of as much of this as possible, that conference should be NeurIPS. If one can’t visit, all the learning material is available online. While the field surges forward at a breakneck pace, certain regions and communities are being left behind. This in turn creates an opportunity for the vast intellectual capital of these communities to contribute in a meaningful way to societal technological progress. I can only hope that you – yes you reading this – have been motivated a bit by these words to be part of the solution.
Until next time then.
